Content
Disable MV prediction from co-located candidates of reference frame (relevant for HEVC)
Flexible Macroblock Ordering (relevant for H264/AVC)
Data Partitioning (relevant for H.264/AVC)
Introduction
“Resiliency is the ability of a system to gracefully handle the failures and recover from failures as soon as it can”
In the context of the current monologue “Error Resilience” means – “friendliness” of generated bitstream for a decoder to cope with potential bitstream errors (like bit flip-flops or packet loss). Bear in mind – exploitation of inter-dependency among video frames causes a compressed video to be very sensitive to data loss.
To cope gracefully with bitstream errors (e.g. packet loss in media streaming applications) a decoder is expected to perform the following three basic operations:
Error detection (promptly)
For example, the decoder has not decoded all MBs in a frame/slice but the start code is seen (or sensed), this is a direct indication for a bitstream error or a packet loss (in case of internet streaming). In such case the decoder should derive that the bitstream got corrupted. Although the decoder can’t know in a reliable way where exactly the error is located (even in which MB).
Theoretically the decoder can monitor statistics of motion vectors and if the motion vectors start to behave chaotically and get super-large magnitudes this is highly likely due to a bitstream corruption.
More indication, the decoder has finished a frame/slice but no start code (of the next NAL) is sensed, this is a direct indication of a bitstream error.
Error recovery (i.e. to re-sync and resume decoding)
Decoding re-syncing can be to the next frame or slice (if frames are divided into slices) or even to the next GOP. For some applications where low latency is not a requirement, the decoder can ask to retransmit the corrupted frame or slice.
Error concealment
E.g. to replace a corrupted area with co-locate one from a clean previous frame.
Due to predictive nature of most of video compression methods, a bitstream error generates a corruption wave which is propagated in both spatial and temporal (i.e. along next frames due to temporal prediction) directions. The corruption wave is actually a space-time wave which can finally destroy the whole scene unless is blocked and cleaned by IDR frame or intra-refresh sequence.
In spirit of No Free Lunch Theorem the error resilience enhancement is always at the cost of bitrate and/or quality. The error resilient and compression efficiency generally requires a tradeoff, and it is difficult to achieve both the strong error resiliency and the good coding efficiency simultaneously. For example, if the bitrate is fixed or capped in your ecosystem then an enhancement of the error resilience would tend to degrade visual quality.
It’s worth mentioning that if the target bitrate is not capped then any enhancement of error resilience increases the bitrate (since any enhanced error resilience consumes more bits). However, more bits in turn elevates likelihood of the bitstream error. It’s not uncommon when an enhancement of the error resilience gets counter-productive (i.e. it incurs more errors) in an ecosystem where the bitrate is not capped.
Error Resilience Methods
Many techniques have been discussing in the literature how to improve the error resilience. i enlist some of the techniques:
a) [Naive Method – by replication of frames, i.e. to transmit each frame twice, doubling of the bitrate]
If a decoder detects an error anywhere in a given frame it discards this frame and switches to its replica (which is the next frame and presumably is error-free). Consequently, a serious impact on visual quality since the actual bitrate is reduced twice (due to doubling of the bitrate).
There is one scenario when this method probably can be effective:
Let’s suppose that your ecosystem utilizes H.264/AVC and you decide to migrate to more coding effective standard say H.265/HEVC (it’s reported HEVC produces a bitrate at least by 30% smaller than that of AVC without compromising visual quality). Upon the migration to HEVC you can transmit each third frame twice without perceptual quality degradation (since your total bandwidth is intact) and with enhanced error resilience (1/3 of bitstream errors are surely concealed seamlessly).
Some NALUs like SPS and PPS headers are very sensitive to errors, it’s not uncommon to transmit these NALUs twice in separate packets.
Each slice can be decoded independently from other slices (provided that deblocking and other in-loop filters are off across slice boundaries) and can be transmitted in separate packets. An advantage of slicing is obvious, the loss of a packet carrying a single slice does not break decoding of the other slices of the picture, only a part of the picture is corrupted.
If an encoder divides each frame into slices or tiles (bear in mind AVC/H.264 supports only slices while HEVC/H.265 supports both slices and tiles, AOM AV1 supports only tiles) then the reception of a corrupted slice confines visual artifacts to that slice.
Thus, the visual degradation is spatially limited within boundaries of the corrupted slice. However, due to temporal prediction visual artifacts can cross slice boundaries in next frames and finally destroy the whole scene.
It’s worth mentioning that massive division a frame into slices/tiles degrades the coding efficiency due to breakage of predictions across slice/tile boundaries (plus slice/tile headers).
The corruption wave is effectively blocked at the beginning of the next GOP (at the next IDR frame). Therefore the shorter GOPs (of course in number of frames) the shorter periods of visual artifacts appearance. However, coding efficiency is deteriorated due to frequent transmission of IDR frames (since temporal redundancy is not exploited in IDR frames).
d) [Intra-refreshment or Disperse more intra MBs]
Modify intra/inter decision heuristic in an encoder (if it’s configured) to produce more intra MBs (bear in mind constrained_intra_prediction flag must be on, otherwise this method is pointless). Intra MBs effectively block locally propagation of the space-time corruption wave (incurred by a bitstream error). Alternatively, Intra Refresh methods can be also considered.
Reduce motion estimation area in the encoder. In such case the velocity of the corruption space-time wave is also reduced.
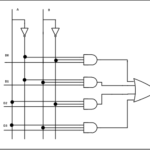
f) Relevant for HEVC/H.265 – [Disable MV prediction from co-located candidates of reference frame]
In HEVC/H.265 the set of candidates for MV prediction can include a temporal candidate (or co-located candidate) from a pre-defined reference picture (if the slice header parameter – slice_temporal_mvp_enabled_flag=1). However, if the reference frame is corrupted then the temporal candidate might be “garbage”. So, it’s recommended set slice_temporal_mvp_enabled_flag to 0 to avoid using “garbage” data for prediction.
g) Relevant for H.264/AVC Baseline Profile – FMO (Flexible Macroblock Ordering)
FMO allows MBs to be grouped in slice-groups in non-scan order and each of slice-group can be further partitioned into more slices.Various FMO types are available, but the most efficient for error resilience is “checker board”:

Gray MBs belong to slice-group0 and white MBs belong to slice-group1
if slice-group-1 gets corrupted then MBs of this slice-group can be interpolated from correct neighboring:

* Taken from “Error Concealment Techniques for H.264/MVC Encoded Sequences”, by Brian W. Micallef et al.
In the figure above the left frame is original which is split into two slice-groups in “checker board” order. The second slice-group gets corrupted (illustrated by the middle frame). The right frame is error-concealed frame (via interpolation).
“Checker Board” FMO has two drawbacks:
1) coding efficiency is degraded due to distant predictions
2) FMO is allowed in Baseline profile and in this profile CABAC is disallowed, As a result a penalty in coding efficiency is 10-12% (CAVLC is not such effective as CABAC).
Notice that FMO mechanisms have rarely been used in practice.
This mode is also called – Layered Coding. In this method, which is also called Scalable Video Coding (SVC), the source is coded into a Base Layer and one or more Enhancement Layers (EL). At the receiver, the layers are superimposed on each other hierarchically. The quality of the video is gradually enhanced by the number of received enhancement layers. The Base Layer is usually most protected, since bit errors in the base layer invalidate all enhancement layers. Data loss of EL cause much less degradation of video quality than loss of data in Base Layer (because a decoder can always switch to Base Layer).
Both H.264/AVC and H.265/HEVC supports scalable (layered) video coding: spatial and SNR (quality) scalability. Typical scalable stream consists of base layer (reduced resolution or quality) and enhancement layer(s).
If data in an enhancement layer gets lost then a player can switch to the base layer (in case of the spatial scalability the player have to upscale video). However, if data in the base layer gets lost then traditional methods of error concealment should be applied. So, enhancement layers are of lesser importance than the base one.
Disadvantages:
- Decoding times tend to be longer.
- Not all decoders (both sw and hw) support scalable video.
Use case: SNR dual layered coding (the enhancement layer and the base layer). The enhancement layer does not use the base layer as reference, therefore the base layer is transmitted as redundant pictures. Despite the enhancement and the base layers are independent a decoder decodes both.
If a packet loss occurs in the enhancement layer the decoder immediately switches to the base layer until the next key frame. If a packet loss occurs in the base layer no effort is required, the decoder re-synchronize at the next key frame.
Because the inter-layer prediction is not exploited base layer adds an additional overhead (say 20%-25%).
i) Data Partitioning (relevant for H.264/AVC)
Despite H.264/AVC standards supports Data Partitioning, i’ve never seen a stream encoded in Data Partitioning mode.
In Data Partitioning a slice is split up to three parts (data partition A, B, and C). The data partition A contains the header information such as MB types, quantization parameters,
and motion vectors, which are more important should be better shielded. The the loss of the data partition A makes the other two partitions useless.
The data partition B contains intra coded block patterns (CBPs) and transform coefficients of intra-blocks.
The data partition C is sent for P or B slices and contains Inter CBPs and coefficients of inter-blocks.
Note: I-frames have higher effect on video quality. Consequently it’s recommended to enhance error-resilience of I-frames (e.g. to transmit with higher protection among other frames). Such approach is called content-aware transmission. and large frame inter-dependency.
Error Concealment Methods
Block Copy method – each damaged block in a corrupted frame is copied from the corresponding co-located block of the previously decoded frame.
MV Copy method – the MVs and reference indices of the colocated blocks in the previously reference frames are applied to conceal the missing or damaged blocks of the current frame. Thus, the corrupted frame is assumed to have the same motion as its reference frame.
Note: Copy methods are restrictive because they non-effective for I frames or frames with scene changes.

23+ years’ programming and theoretical experience in the computer science fields such as video compression, media streaming and artificial intelligence (co-author of several papers and patents).
the author is looking for new job, my resume