
Introduction
Generally speaking there three level of parallelism that can be exploited to speedup the video encoding/decoding processes:
1) GOP-level: each core takes its own GOP and processes it.
2) Frame Level: there are three variants:
a) B-frame parallelism, if GOP structure contains two consecutive B-frames (IPbbPbbPbb..., small letter denotes – not used for reference) then two B frames can be encoded/decoded in parallel (bear in mind they are not used for reference and are non-dependent each other).
b) Non-reference P-frame, to enhance error resilience non-reference P-frames are used (for details pls. look here):
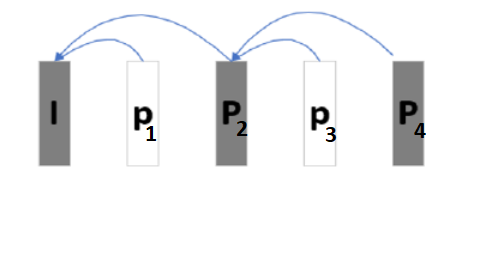
So the pairs p1,P2 and p3,P4 can be encoded/decoded in parallel.
c) Frame-Delayed encoding parallelism.
The first core starts encoding the first CTU raw of the first frame by restricting motion vectors to refer to the first raw.
Upon finish of the first CTU raw by the first core, the second core starts encoding of the first CTU raw of the second frame (since reference already is ready) while the first core begins encoding of the second CTU-raw of the first frame. ….
3) Tiles-Based, Sliced-Based, wavefront parallelism
Frame is divided into self-contained tiles and all tiles are processed in parallel. Similarly each frame can be divided into slices and each slice is processed in parallel. In addition, some standards support wavefront mode, see below in the post.
The coarsest parallelization level is GOP-based, the whole video sequence should be available and it’s broken in GOPs (Group of Pictures) and each GOP is processed completely independent from the other GOPs. GOP-based method has its own disadvantage a visual quality flickering can be observed at GOP boundaries.
Definition: Frame-level parallelism means a set of tools of processing multiple frames at the same time.
If all frames are I-frames then they can be processed at the same time (provided that the frames are available) due to lack of temporal dependencies. In general case due to temporal dependencies between frames the processing of some frames are lagged.
Successive non-reference B-frames between P-frames can be processed at the same time. However, this approach is limited since two or maximum three consecutive B frames are signaled between the P frames.
We describe two schemas of the frame-level parallelism: slice-based and tile-based.
B-Frame Parallelism
If successive non-reference B-frames are used (like IPBB GOP structure) then these B-frames can be encoded in parallel
Slice-based Picture Level Parallelism
The first thread starts the k-th frame, the second thread waits until a several mb-rows of the k-th frame have been completed. Then the second thread commences encoding of (k+1)th frame, search area is already available.
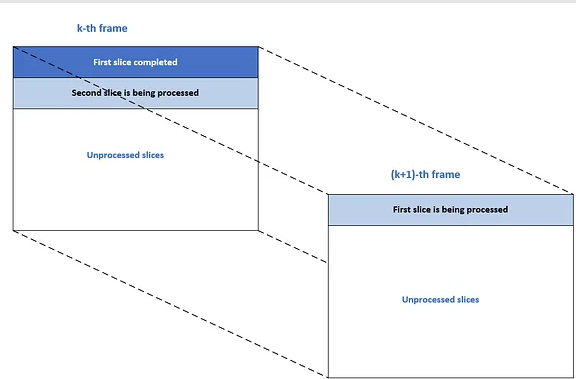
Disadvantage of slice-based parallelism is that vertical motion estimation is restricted.
Use case: x265
To enable frame-level parallelism you need disable WPP (use ‘–no-wpp’) and apply ‘–frame-threads’ (no co-existence of WPP and frame-threads) by setting ‘–frame-threads N’, where N is the number of threads.
Example (2 concurrently encoded frames):
x265 –input a.yuv –input-res 3840×1744 –fps 24 –b-adapt 0 -b 0 –ref 1 –frame-threads 2 –no-wpp –rc-lookahead 2 -o test.h265
–frame-threads is number of concurrently encoded frames, by default the number of concurrently encoded frames is autodetected. If you use ‘–frame-threads 1′ you would get worse performance.
Example [ encoding 100 frames of the sequence “Crowd Run”]
x265 –input crowdrun1080p50fps.yuv –input-res 1920×1080 –fps 50 –b-adapt 0 -b 0 –ref 1 –frame-threads [1|2] –no-wpp –rc-lookahead 2 -f 100 -o test_frame_threads[1|2].h265
–frame-threads = 1
encoded 100 frames in 101.85s (0.98 fps), 16670.37 kb/s, Avg QP:34.23
–frame-threads = 2
encoded 100 frames in 78.20s (1.28 fps), 16670.37 kb/s, Avg QP:34.23
Tile-based Picture Level Parallelism
Each picture is divided in same grid of tiles (tiles are used to split a picture horizontally and vertically into multiple sub-pictures), each tile is self-contained to enable parallel processing . The first thread completes several top-left tiles of frame 0 and then the second thread starts the frame 1 with motion search area resting on already processed tiles of the frame 0 and so on:
The first core starts processing tiles (Tile0, Tile1, Tile4 and Tile5) of the frame 0. Upon completion of processing tiles 0,1,4 and 5, the second core starts processing Tile0 of the second frame using already processed tiles from the frame 0 as reference etc:
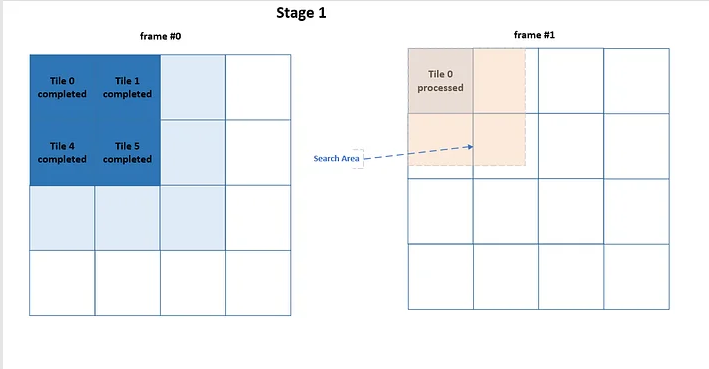
Unlike to Slice-level parallelism, the search area is square and vertical motion estimation is not restricted.

23+ years’ programming and theoretical experience in the computer science fields such as video compression, media streaming and artificial intelligence (co-author of several papers and patents).
the author is looking for new job, my resume




Wow! This could be one particular of the most useful blogs We’ve ever arrive across on this subject. Basically Magnificent. I am also an expert in this topic therefore I can understand your effort.
Lovely just what I was looking for.Thanks to the author for taking his clock time on this one.
Good day very cool site!! Guy .. Beautiful .. Wonderful .. I’ll bookmark your site and take the feeds additionally…I’m happy to search out so many helpful information here in the put up, we want develop extra strategies in this regard, thanks for sharing.
Appreciating the hard work you put into your website and detailed information you present. It’s nice to come across a blog every once in a while that isn’t the same outdated rehashed material. Wonderful read! I’ve bookmarked your site and I’m including your RSS feeds to my Google account.
Great work! This is the type of information that should be shared around the net. Shame on Google for not positioning this post higher! Come on over and visit my site . Thanks =)
It is really a nice and useful piece of information. I¦m glad that you just shared this useful information with us. Please stay us up to date like this. Thank you for sharing.
Excellent website. A lot of helpful information here. I am sending it to several pals ans also sharing in delicious. And obviously, thank you to your sweat!
Yeah bookmaking this wasn’t a risky determination outstanding post! .
I’d have to test with you here. Which is not one thing I normally do! I get pleasure from reading a put up that may make people think. Additionally, thanks for permitting me to remark!
Undeniably believe that which you said. Your favorite reason appeared to be on the net the easiest thing to be aware of. I say to you, I certainly get annoyed while people consider worries that they plainly don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having side-effects , people can take a signal. Will probably be back to get more. Thanks