
General
H264 – HEVC – VP9 Features List
Detailed Explanation of Features
Non-Displayed Frames/Superframes
HRD – Hypothetical Reference Decoder
Transform Size Greater Prediction Size
Precision of Arithmetic Machine
Probability Models Adaptation within Frame
General
It’s challenging to compare different codecs (even the same video standard) in a fair and unbiased manner, because we actually compare specific implementations of the standards (e.g. x265 versus SVT-HEVC). Implementations can be good and can be poor (believe me), there is a noise in such comparison and the potential of each standard might be not revealed.
This paper is inspired by the white paper of Beamr Imaging “Choosing the Right Codec: Comparing HEVC & VP9″
In this paper i compare features of each video compression standard and not its specific implementation. i intend to emphzsize the following points:
- coding efficiency ( bit-savings for a given quality or a gain/penalty in quality given same bitrate)
- memory usage
- friendliness for parallelization
How video standards are compared nowadays? They are not compared, theirs implementations (codecs) are compared, the only way to compare video standards is feature by feature analysis:
- Selection different types of video Content: e.g. sports, head and shoulders, video conferencing, motion picture, computer-generated imagery etc.
- Configure each video codec in a similar manner (i deliberately use ‘similar’, because it’s not always possible to align video codecs exactly):
- similar GOP length in pictures and GOP structure
- similar picture prediction structures: same number of references, same number of forward and backward reference, similar weighting parameters, etc.
- Similar Rate Control settings
For each video sequence and for each fixed QP two codecs are run and average distortions (over all frames in the sequence) and bitrates are derived. Then two points are plotted in corresponding rate-distortion graph. Then BD-rate is computed if at least four points are present.
Note: it’s worth mentioning that VP9 is a sort of “transition” standard to the final aim – AV1.
There is a more friendly paper (i am a co-author) – “Choosing the Right Compression Technology – Comparing VP9,AVC, and HEVC“
H264 – HEVC – VP9 Features List
| Features | H264 | HEVC | VP9 |
|
General Features |
|||
| Start Codes | yes | yes | no |
| Containers | mp4,ts, mkv,.. | mp4,ts, mkv,.. | IVF, WebM |
| Reference Frame Scaling | no | no | yes |
| Non-displayed Frame/Superframe | no | no | yes |
| HRD | yes | yes | no |
| HDR | yes | yes | in WebM |
|
Frame Level Features |
|||
| Slices | yes | yes | no |
| Tiles | no | yes | yes |
| Probability Models Adaptation | no, reset at start of slice | no, reset at start of slice | yes |
| Superblock Size | 16×16 | 64×64 | 64×64 |
| Quadtree Partitioning | no | yes | yes |
| Segmentation | no | no | yes |
|
Intra Prediction Features |
|||
| Below-Left Intra Predictors | no | yes | no |
| Intra Prediction Modes | up to 9 | 35 | 10 |
| Filtering Neighboring Samples | yes
(except 4×4) |
yes
(except 4×4) |
no |
|
Inter Prediction Features |
|||
| Asymmetric Inter Partition | no | yes | no |
| Weighted prediction | yes | yes | no |
| Bi-Prediction | Yes | Yes | Yes, only as superframe |
| Number of References | up to 16 | up to 16 | 3 |
| Sub-pel Interpolation | ¼ for luma | ¼ for luma | 1/8 for luma, 3 optional modes |
| MV Prediction | median | competitive | competitive |
|
Transform Features |
|||
| Custom quantization matrices | yes | yes | no |
| Transform Size greater Prediction Size | No | Yes | No |
| Transform Sizes | 4×4,8×8 | Up to 32×32 | Up to 32×32 |
| DST | no | yes | yes |
| Transform Skip | no | yes | no |
|
VLC Features |
|||
| Precision of Arithmetic Machine | 10 bits | 10 bits | 8 bits |
| Models Adaptation within Frame | yes | yes | no |
|
In-Loop Filtering |
|||
| Deblocking | yes | yes | yes |
| SAO | no | yes | no |
To best my recollection the most full comparison of HEVC versus H264/AVC in subjective metric (MOS) is presented in the paper “Video Quality Evaluation Methodology and Verification Testing of HEVC Compression Performance”, by Thiow Keng Tan et al., 2016 . The main conclusion of the article:
“HEVC test points at half or less than half the bit rate of the AVC reference were found to achieve a comparable quality in 92.5% of the test cases”
Detailed Explanation of Features
Start Codes
Lack of start codes in VP9 makes error resynchronization challenged. Consequently, the error resilience of HEVC is in virtue better than that in VP9. Frankly speaking at the start of key frame there is a sync-code 0x498342, but how to guarantee that this pattern is not emulated within VP9 stream.
On the other hand there is a clear advantage of the lack of start codes – no need for anti-emulation bytes (like 0x03 emulation prevention byte in H264/HEVC) and consequently decoding process is slightly easier.
Containers
The VP9 elementary stream is containerized with IVF or WebM (a subset of MKV) while HEVC/H264 elementary streams are containerized in MP4, Mpeg-system (TS), MKV,….
Recently Mpeg committee has adopted a support for vp9. Moreover, the new version of ffmpeg has been released which as declared can convert vp9 stream (in format of IVF or WebM) into mp4 file, however i could not convert vp9 webm-file or ivf-file into mp4 format (ffmpeg issues the error – “Application provided invalid, non monotonically increasing dts”).
Additional info on efforts in incorporation of VP9 into DASH and ISO Media File System can be found at https://www.webmproject.org/vp9/mp4/
Due to the lack of start codes in VP9 elementary streams, the elementary stream can be played in a very strict manner – without skip, fast forward and other tricky modes.
Reference Frame Scaling
In VP9 each frame may make reference to three reference frame buffers selected from a pool of up to eight stored reference frames, the used reference frames are signaled by a syntax element in the frame header.
VP9 Only Feature. In VP9 each new inter frame can be coded using a different resolution than the previous frame. So, to enable inter prediction the reference data is scaled up or down accordingly. The scaling filters are 16th pel accurate, 8-tap. Notice the amount of up/down scaling is limited to be no more than 16x larger and no less than 2x smaller.
Motivation of Reference Frame Scaling feature is to enable seamless on-the-fly bitrate adjustment by resolution change. In HEVC or H264 you need send IDR with a new SPS/PPS to change the resolution. IDR pictures produce spikes in bitrate and discontinue temporal prediction.
Non-Displayed Frames/Superframes
VP9 Only Feature. VP9 supports non-displayed frames. However, non-displayed frames cause a problem when putting the bitstream in a container, since each “frame” or sample in the container should be a displayable entity.
To resolve this problem, VP9 introduces a tricky concept of a super-frame:
Superframe – one or more non-displayable frames preceded one displayable frame (all frames strung together as one chunk of data).
Usually a superframe contains single non-displayed frame followed by single displayed frame.
Motivation: to enable Bi-prediction and avoid patent infringements.
HRD – Hypothetical Reference Decoder
VP9 has not HRD. In many applications HRD is must since this mode restricts bitrate fluctuations and enable ‘smooth’ decoding,
HDR – High Dynamic Range
Both VP9 and HEVC/H264 supports 10/12 bits per sample but this is not sufficient. For HDR play-out it’s necessary to convey EOTF function and other relevant parameters (which are used in various HDR ecosystems like PQ or HLG or HDR10). In HEVC/H264 EOTF, color space and other HDR params are signaled in VUI section of SPS. Therefore HDR TV set can playback hevc elementary streams. Notice that MPEG System has a limited indication on HDR parameters (in HEVC descriptor only HDR color gamut is specified but no indication on EOTF function).
Unlike to HEVC, VP9 elementary stream does not carry any parameter specifying EOTF, color primaries etc. These parameters are signaled in WebM container in the section ‘colour’ (recently added, Segment → Tracks → TrackEntry → Video → Colour). For details pls. see: http://www.webmproject.org/docs/container/#colour
Slices
VP9 does not support slices at all while HEVC and H264 do support. Slices are tailored for the following purposes:
- Network Packetization (MTU length matching) – the length of an encoded tile rarely fits to a predefined MTU size while the slice size can be easily adapted to the MTU length.
- Error Resilience – fast resynchronization in case of bitstream errors or packet loss.
- Parallel processing (encoding/decoding) – slices are self-contained, excepting deblocking, notice that deblocking across slice boundaries is optional in HEVC (slice_loop_filter_across_slices_enabled_flag) and mandatory in H264.
- Low-delay – to start transmission of the encoded data earlier, a current slice may be already transmitted, while encoding the next slice in the picture.
Hence HEVC/H264 have an advantage against VP9 to make better network packetization, to enhance error resilience, to make friendly parallel processing, to realize low-delay.
Tiles
Tiles are supported by HEVC and VP9 (not supported by H264) but there are significant differences between HEVC and VP9 tiles.
- In HEVC all tiles are decoded simultaneously (even deblocking can be optionally switched off across tile boundaries to make tailes self-contained).
- As per VP9, because the horizontal prediction across tile boundaries is not broken (although the vertical prediction is broken between tiles), this means that only tiles in same row can be processed simultaneously. Actually rows of tiles in VP9 are self-contained and can be processed in parallel. For example, 2×2 tiles can be decoded simultaneously with 2 cores, but not with 4 as in HEVC.
- In HEVC tile sizes can be adapted to workload balancing (for example, if left part of a frame is ‘simple’ and the right part is ‘heavy’ we can divide the right part into more tiles than the left one and consequently to achieve better workload balancing).
- As per VP9, tiling is uniform (all tile widths are equal excepting probably the right-most tiles, all tile heights are equal excepting probably the bottom-most tiles).
Probability Models Adaptation
In H264/HEVC probability models are updated within a slice, but at the start of each picture/slice/tile the models are reset. Hence, each slice/tile is self-contained from the arithmetic machine’s view. Resetting of probability models at the start of each picture/slice/tile is at the expense of coding efficiency.
VP9 takes advantage of entropic redundancy between frames (i.e. probability models can be not-resetting at frame level). Disadvantage of VP9 – the probability models are not updated within a frame (i.e. VP9 keeps probabilities constant during the coding of a frame). Therefore if an encoder chooses “non-relevant” models at the start of a frame the coding efficiency is deteriorated.
In VP9 there are three modes of initialization of probability models at the start of each frame:
- use global models (as in HEVC/H264) – applied in case of parallel decoding and error resilience.
- explicitly transmit new probability models (more suitable for a given frame) in the frame header – useful if an encoder can assess ahead probabilities.
- automatically adjust the probabilities at the end of the frame to match the observed frequencies – be careful at scene cuts when probabilities of the previous frame may be irrelevant.
Analysis:
Fixed probabilities within a frame is a disadvantage of VP9 against HEVC/H264,
non-resetting of probabilities at frame level provides an advantage of VP9 against HEVC/H264.
Unlike to HEVC, VP9’s encoder can’t reset probability models at start of tile therefore full parallization can’t be achieved (the arithmetic engine should be decoupled from the rest of encoding/decoding process).
Superblock Size
In HEVC super-block (CTU) size can be 64×64 or 32×32 (and even 16×16 for low levels). It’s worth mentioning that 64×64-sized CTU brings nearly 12% bitrate reduction on the average compared with 16×16-sized CTUs as reported at “Entropy-Based Fast Largest Coding Unit Partition Algorithm in High-Efficiency Video Coding”, Mengmeng Zhang et al., 2013. Notice also that the authors checked a wide range of resolutions.
On the other hand it’s also reported in other papers that 32×32 CTU mode is beneficial for small resolutions. Because the authors of the above article didn’t check 32×32 CTU mode (only 16×16 CTU) i intend to accept that 32×32 CTU mode has a gain in coding efficiency for small resolutions.
Anyway, because our products work with high resolutions the flexibility of HEVC in selection of superblock sizes can’t be considered as an advantage compared with VP9.
In VP9 super-block size is fixed to 64×64.
Quadtree Partitioning
Quadtree partitioning of HEVC and VP9 are similar therefore i see no benefit of HEVC against VP9 or vice versa.
Both HEVC and VP9 superblock is divided up to 8×8 coding units and each coding unit in turn is split into prediction and transform blocks. It’s worth mentioning that in HEVC each inter CU is independently split into transform blocks (transform tree) and into prediction blocks (prediction tree), i.e. a transform block may contains several inter prediction blocks. In VP9, transform block is always smaller or equal to prediction block.
For illustration, HEVC 64×64 CTU (superblock) division:
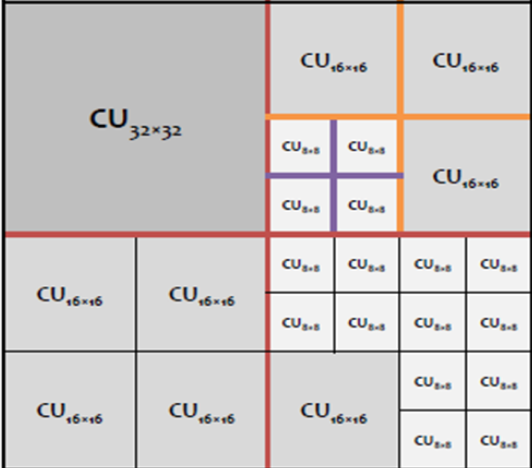
Each leaf block can be either Inter or Intra.
Segmentation
Only VP9 supports a segmentation (optionally). What’s the segmentation? In the simplest form: the segmentation groups together blocks with similar characteristics.
Frame is divided into up to 8 segments in a custom order. The number of segments and types are transmitted in the frame header (explicitly or temporally predicted). In Segmentation mode each block carries segment_id (affiliation to a specific segment) if segment map update flag is set in the frame header (otherwise segment_id is derived from co-located block of the previous frame. All blocks belong to a specific segment share one of the following parameters (i.e. this parameter is not transmitted and derived by a decoder by means of segment type):
- quantizer
- loop filter strength
- prediction reference frame
- block skip mode that implies the use of a zero motion vector and that no residual case.
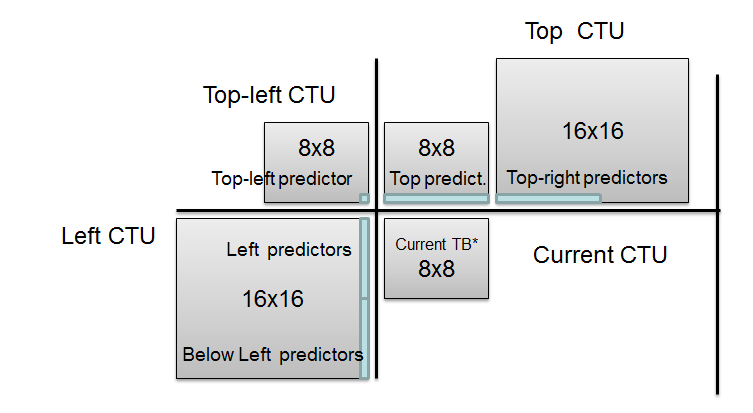
Below-Left Intra Predictors
In contrast to VP9, in HEVC below-left neighboring samples are exploited for intra prediction.
Motivation: wide range of prediction block sizes (from 4×8 to 64×64) makes availability of bottom-left samples to be more frequent
Intra Prediction Modes
In H264 up to 9 intra prediction modes used (only 4 intra modes for 16×16 blocks and 9 modes for 4×4 and 8×8).
In HEVC the number of modes is huge – 35 (33 angular predictions for both luma and chroma and two non-directional predictions – DC and Planar).
Note: regarding to Planar mode of HEVC in the paper “RESEARCH ON H.265/HEVC INTRA PREDICTION MODES SELECTION FREQUENCIES” by Sharabayko M.P reported that the planar prediction is performed for 20% of PUs, while about 10% are predicted by DC. Thus, Planar mode is more popular than DC.
In VP9 the number of intra modes is 10 (8 angular prediction and two non-directional modes – DC and TrueMotion). Notice that DC prediction in VP9 is pretty similar to that of HEVC/H264.
HEVC has clear benefits in exploitation of spatial redundancy by intra predictions against VP9. Moreover, Planar mode of HEVC is much effective than corresponding TrueMotion mode of VP9.
Filtering Neighboring Samples
In HEVC an adaptive smoothing filter is applied on neighboring samples of an intra-prediction block (excepting 4×4 blocks). The filter is applied according to the intra prediction directionality and block size. The intention is to avoid steps in the values of reference samples that could potentially generate unwanted directional edges in the prediction block and consequently could deteriorate coding efficiency.
In VP9 no pre-filtering is applied on neighboring samples. As a result (especially for large intra blocks) unwanted contouring might appear in predicted and even in reconstructed block (leading to observable artifacts).
Asymmetric Inter Partition
In VP9 the block decomposition has 4 partitioning modes: none, horizontal, vertical and split:
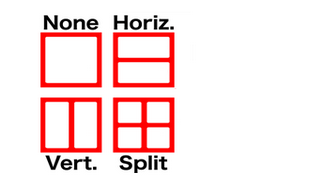
In VP9, the prediction block size 4×4 is allowed while in HEVC the minimal prediction granularity is 4×8 and 8×4. For high-resolution video the 4×4 prediction blocks are not “popular”. In HEVC in addition to above four modes there are four assymetric partitions for blocks greater 8×8:

Definitely HEVC has an advantage in coding efficiency against VP9, although “Choose Partition” methods are expected to be more complex in HEVC since there exist more candidates.
Weighted prediction
In H.264/HEVC the weighted prediction is enabled while VP9 does not support weighted prediction at all.
Weighted prediction is especially effective in case of fades and in compensation of local brightness changes (see “Region-based weighted prediction with improved global brightness detection for H.264 Encoder” by Prathiba N S et al.)
Bi-Prediction
VP9 does support bi-prediction but in a tricky way coined “compound prediction” (which is just another word for bi-prediction) in order to avoid patent infringements. In VP9 B-frame can be represented as a supreframe (i.e. a pair of two frames):
- the first frame is non-displayable frame containing all residuals and motion data
- the second frame is displayable and it consists of nothing but 64×64 blocks with no residuals and 0,0 motion vectors that point to this non-displayed frame,
Superframe adds additional overhead (the second frame consumes bits), therefore HEVC has a benefit in coding efficiency against VP9 (since in case of HEVC bi-prediction MVs and residuals are transmitted directly).
Number of References
H264 and HEVC support up to 16 reference frames(although for high levels up to 4). Common case to keep 4 reference frames (although for fast modes the number of references is 2).
VP9 supports up to 3 active reference frames and 5 reference frames in pool. So, VP9’s decoder has to keep 8 reference frames at all times (in case of 4K it’s lot of memory). In case of HD/4K HEVC/H264 decoder should contain up to 4 reference frames. For each inter frame 3 reference frames are picked of the pool of 8 frames to use for inter prediction. Upon encoding/decoding there is an option to put the current frame in any of these 8 slots evicting a frame was there before.
In case of HD/4K video VP9 decoder requires a huge amount of memory to keep 8 reference frames while HEVC decoder needs at most 4 slots. So, HEVC decoder uses 2x fewer memory.
Generally speaking, increasing the number of references above 3 or 4 has negligible effect on coding efficiency (except video excerpts with short periodic movements), see the book “Video Encoding by the Numbers” by Jan Ozer, the sub-section “Reference Frames“
Note:
VP9 supports Alternative Reference Frames which are used purely for reference and are never actually displayed. These frames are identified as invisible using a flag in the frame header. A possible use of Alternative Reference Frames is to code an out-of-order future frame (B-frame) to enhance coding efficiency by incorporating forward prediction.
MV Prediction
For low bitrates motion data can be comparable to residual data. Therefore effective coding of motion data is important for low-bitrate cases.
H264 – median MV prediction of surrounding causal MVs. Unlike to H264, both HEVC and VP9 adopted the competitive motion vector prediction (i.e. several candidates are competing for the prediction and the best candidate is signaled).
HEVC supports two motion prediction modes:
- Merge mode – motion data is completely inferred, similar to Direct/Skip mode of H264.
- AMVP (Advanced Motion Prediction) – inferred only motion vector (MV) predictors and MV difference is signaled.
The set of candidates in both modes can include a temporal candidate (or co-located candidate), this feature improves both coding efficiency and error resilience.
In addition HEVC has a particular parallel merge mode (specified by PPS parameter log2_parallel_merge_level). This mode enables parallel derivation of the merging candidate lists for all blocks in a CTU (super-block) by referencing to motion data of given CTU neighbors.
VP9 – uses up to 3 MV candidates for block sizes ranging from 4×4 up to 64×64: two spatial candidates taken from up to 8 nearby casual MVs (incl. temporal MV) and zero MV. For prediction up to two candidates are used from the list of the MV candidates. Notice that the candidates use the same reference picture, followed by a temporal predictor. If the search process does not fill the two-entry prediction MV list, the surrounding blocks are searched again but this time the reference doesn’t have to match. Finally, if the prediction MV list is still not filled, then 0,0 vectors are stuffed.
For each inter block four motion vector prediction modes are available for choice:
- New MV – Use the first predictor (or the first entry in the list) of this prediction list and add in a delta MV (which is transmitted in the bitstream)
- Nearest MV – use the first predictor intact, no delta transmitted
- Near MV – use the second predictor, no delta transmitted
- Zero MV – use 0,0 as the MV value.
Note: In HEVC in AMVP mode the number of candidates is 2 as well as in VP9. However, in HEVC Merge mode the number of candidates is up to 5 (chosen optionally). Moreover, candidates from with different references are also considered (after a corresponding scaling). On the other hand VP9 has a special mode Zero MV which is relevant for background coding.
Sub-pel Interpolation
In HEVC sub-pel precision is ¼ for luma and ⅛ for chroma respectively. The interpolation filters for both luma and chroma are fixed (non-adaptive):
- For luma a fixed 8-tap filter is applied for both half-pels and quarter-pels. The luma interpolation process consists of two stages: horizontal and vertical filtering. Intermediate results after the horizontal stage are within 16-bits accuracy (if bitDepth>8 then corresponding right shift is applied to keep 16-bits dynamic range). After the second stage, the results are right-shifted according to bitDepth to guarantee the dynamic range up to 16 bits.
- For chroma a fixed 4-tap filter is used for all fractional positions.
In H264 sub-pel precision is ¼ for luma and ⅛ for chroma respectively (as in HEVC). The interpolation filters for both luma and chroma are fixed (non-adaptive). However the interpolation process itself is different from that of HEVC:
- For luma the interpolation is executed in two serial stages for each direction (horizontal and vertical):
- 6-tap filter for half-pels
- bilinear filter for quarter-pels
- For chroma a fixed 4-tap filter is used for all fractional positions (similar to HEVC).
In VP9 subpel precision is ⅛ for luma and 1/16 for chroma respectively, three 8-tap filters can be adaptively chosen at frame-level (i.e. the selected filter is applied to all inter blocks) and at block-level (the filter mode is switchable for each inter block), the same filter is applied to luma and chroma:
- Normal
- Smooth – lightly smoothes or blurs the prediction block
- Sharp – lightly sharpens the prediction block.
The horizontal filter is used to build up a temporary array, and then this array is vertically filtered to obtain the final prediction.
Notes:
- Luma filtering processes in both HEVC and VP9 are similar (8-tap filter), although VP9 uses ⅛ precision for luma. Therefore VP9’s sub-pel interpolation for both luma and chroma is more complex. However, how it’s reported in literature a gain in coding efficiency beyond ¼ precision is small (even negligible). Therefore i don’t see any advantage in 1/8 precision against 1/4 precision.
- Important advantage of HEVC over H264 and VP9 in sub-pel interpolation is a separation of filters for half and quarter pel (can be realized in stages, friendly for HW).
Custom Quantization Matrix
In H264/HEVC there is a custom quantization matrix mode, where each DCT coefficient is quantized with its own quantizer.
In VP9, custom quantization is almost absent (although you can specify different quantization steps for DC and AC).
Note:
It is well known that the human visual system is less sensitive to distortion of high-frequency components than that of low-frequency components. This property has been utilized in both HEVC and H264 by means of custom quantization matrix. In custom quantization matrix the step size increases as the frequency of coefficient increases.
Transform Size Greater Prediction Size
In HEVC, a transform block (TB) may contain several inter prediction blocks (PBs).
In VP9, transform block is always smaller or equal to the prediction block as well as in H264.
Note:
Reported by some experts that prediction discontinuities on PB (Prediction Block) boundaries within TB (Transform Block) are smoothed by transform and quantization. If PB and TB boundaries coincide then the discontinuities are observed increased. Anyway, it’s difficult to decide whether this feature provides a gain in coding efficiency or not.
Transform Sizes
Both HEVC and VP9 support same transform sizes. Although HEVC has a flexibility in selection the maximal transform size (e.g. to reduce decoder’s complexity).
According to JCTVC-G757 (HEVC committee’s document):
- For 8×8 transform required 2.47 cycles per sample
- For 16×16 transform required 3.35 cycles per sample
- For 32×32 transform required 4.59 cycles per sample
The above results are obtained on x86 and ARM with SIMD operations (MMX/SSE on x86, and NEON on ARM).
Note: On Banding Visual Impairments
according to the blog paper “Defeat Banding – Part I”, there is the following statement:
“I find h265, VP9 and AV1 to be even more prone to banding than h264 because of wider block transforms”.
Indeed, VP9 uses 32×32 transform sizes and such blocks might inflict banding. The problem is that metrics like PSNR, SSIM but even VMAF are not sensible to banding.
DST (Discrete Sine Transform)
Motivation for DST for intra prediction blocks:
Intra prediction is based on the top and left neighbors. Prediction accuracy tends to be higher for the pixels located near to top/left neighbors than those away from it. In other words, residual of pixels which are away from the top/left neighbor usually be larger then pixels near to neighbors. Therefore DST transform is more suitable to code such kind of residuals, since DST basis function start with low and increase further which is different from conventional DCT basis function.
Reported 4×4 DST provides some performance gain, about 1%, against DCT. For bigger sizes the gain is negligible.
HEVC uses DST only for 4×4 intra blocks.
VP9 uses two kinds of transforms: regular DCT and asymmetric DST (ADST):
- residual blocks generated by vertical intra prediction modes use ADST vertically and DCT horizontally
- residual blocks generated by horizontal intra prediction modes use ADST horizontally and DCT vertically
- residual blocks generated by True Motion and the down/right diagonal directional intra modes use ADST in both directions
- residual blocks generated by inter modes, DC and down/left diagonal intra modes use DCT in both directions.
Transform Skip
This mode is available only in HEVC and it’s tailored for animation and generated graphics video. According to the paper “IMPROVING SCREEN CONTENT CODING IN HEVC BY TRANSFORM SKIPPING” by Marta Mrak et al., for desktop content the transform skipping achieves gains in the range of 2.4% to 29.7% BD-rate, even for sequences containing a relatively small amount of graphical content, the gains are up to 2.9% BD-rate.
Precision of Arithmetic Machine
In HEVC the arithmetic coder’s precision is 10 bit while in VP9 only 8 bits. i don’t expect any serious impact on coding efficiency or on complexity on a general processor.
Probability Models Adaptation within Frame
In HEVC probabilities are updated within frame while in VP9 the probabilities are fixed and can be changed only at frame level.
This is a real flaw of VP9. Why?
Indeed, in VP9 at random access frame (key frame) a default context is chosen (otherwise this frame can’t be the random access point since its probabilities are dependent on previous frames) if the probabilities are close to the actual probabilities then the entropy of entropy coding is near-optimal. However, in most cases the default probabilities are pretty far to the actual probabilities. In such case VP9 entropy coder is sub-optimal and would produce tons of penalty bits.
In HEVC case, each frame starts with one of default contexts but due to inside-frame context adaptation the probabilities quickly converge to the actual probabilities and the entropy encoder rapidly gets optimal.
So, i expect that in VP9 key frame / next frame ratio is higher than in HEVC. Consequently high peak bitrates would be appear in VP9 stream.
Deblocking
In VP9 there are four deblocking filters modifying up to 14 pixels (7 pixels at each side) while in HEVC there are only two filtering modes (weak and strong) and HEVC deblocking modifies up to 4 pixels (2 pixels a each side). Moreover, in HEVC granularity is 8×8 grid or higher (even if 4×4 transforms used) while in VP9 the deblocking granularity is 4×4 and higher. Therefore VP9 filter is more complex and more effective than HEVC one.
SAO (Sample Adaptive Offset)
SAO is enabled in HEVC only and this filter is tailored to reduce ringing and mosquitos artifacts (notice that this sort of noise tends to get more annoying with large transforms). Consequently SAO improves subjective quality especially for low compression ratio.
Conclusions
Upon checking all features of HEVC and VP9 i come to know that HEVC seems to be superior over VP9.
HEVC is more coding efficient against VP9
HEVC is more complex against VP9
HEVC is more friendly for parallelization against VP9
HEVC has better possibilities for error resilience against VP9
Three flaws in VP9 deteriorate error resilience: lack of start-codes, lack of slices and non-adaptivity of probabilities within a frame.
When arithmetic coding is used error-detection latency is long, i.e. a bit-flip can occur at the start of a frame but detected at the end and the entire frame is corrupted. If the error is detected at the middle of the frame then the second half can be filled by co-located MBs/CUTs/Superblocks.
In the figure below error-detection latency is 2 MBs (usually the latency is much higher):
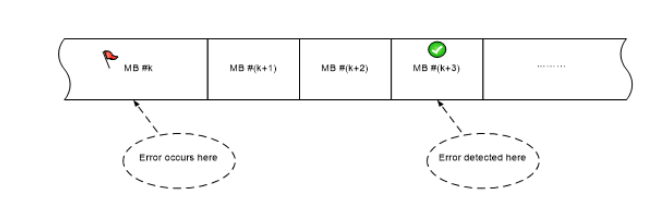
In HEVC/H264 a bitstream error is inevitable detected either at the end of frame when the next start code is sensed but the frame is not decoded completely or when no start code is sensed but the number of CTUs/MBs exceeding the expected amount (according to resolution).
In VP9 (due to lack of start codes) a bitstream error can detected at the middle of the next frame or at the middle of next-next-frame and in such case two or more frames are corrupted (unlike to HEVC where in worst case one frame is corrupted).
Division into slices is useful for error resilience because it guarantees that a bitstream error is inevitable detected prior to the next slice (and only a part of a frame is corrupted).
In error-resilience mode of VP9 each frame is coded with a default set of fixed probabilities (context models in HEVC/H264 jargon), encoder can’t get probabilities from the previous frame since the previous frame may be corrupted prior to arriving a decoder. If the actual context models are close to the default ones then coding is near optimal. However, if no then penalty bits are produced. Consequently, entropy coding is non-effective.
In the paper “A Technical Overview of VP9 – the Latest Open-source Video Codec”, Debargha Mukherjee et al. the following table of BD-Rate comparisons VP9 vs. H264/HEVC is present (x264 is encoder for H264, HM 11.0 for HEVC and libvpx for VP9)
Constant Quality
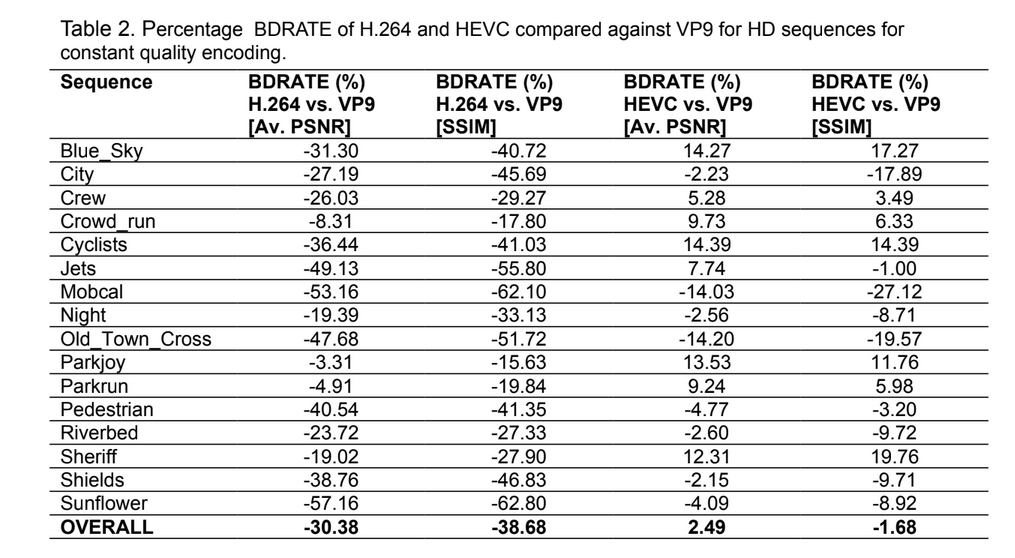
Target Bitrate
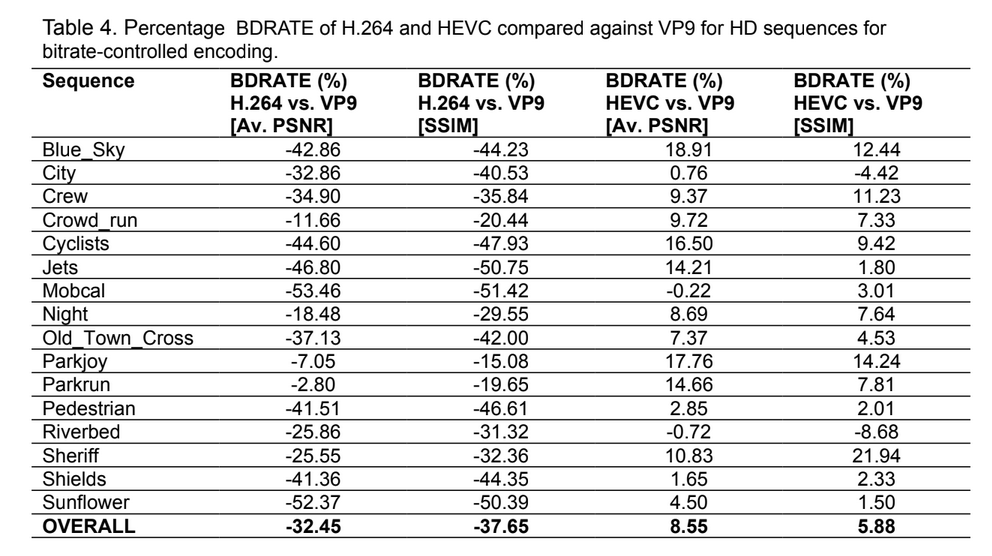
In Bitrate-Controlled mode HEVC outperforms VP9, but in the constant quality mode the situation is controversial.
There is more paper “Quality Evaluation of HEVC and VP9 Video Compression in Real-Time Applications“, by Martin Rerabek, Philippe Hanhart, Pavel Korshunov, and Touradj Ebrahimi
In this paper MOS and PSNR scoring is used to compare three codecs x264 (H264/AVC), HM16.2 (HEVC) and VP9 (vpxenc) for low-latency (the delay up to 150ms) and random access (the delay 0.5-1s) applications. The conclusion: HEVC is better or in some cases similar to VP9:
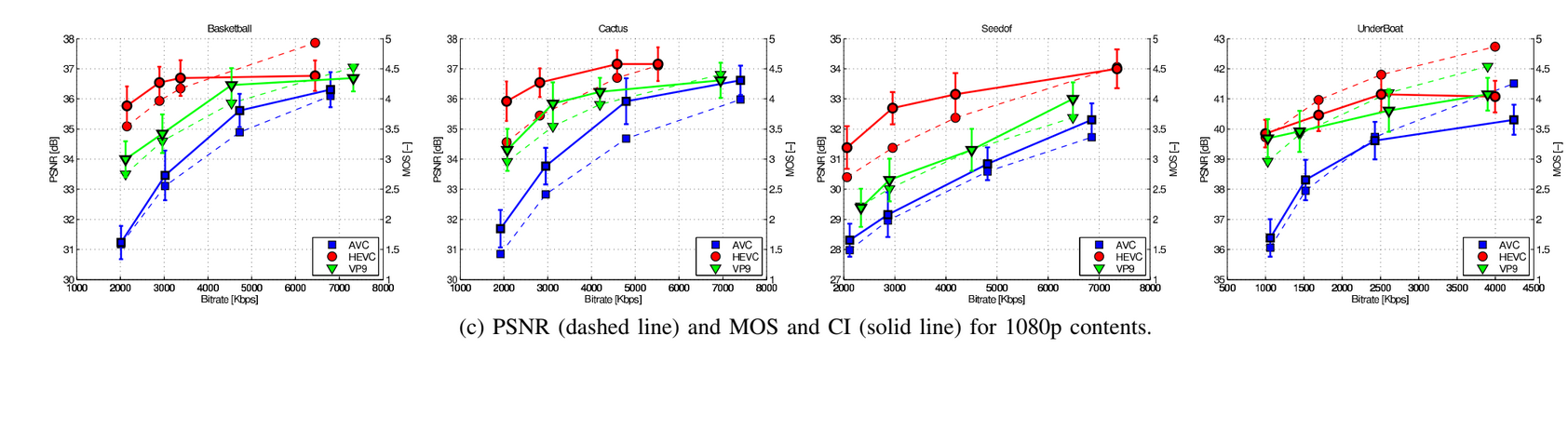

23+ years’ programming and theoretical experience in the computer science fields such as video compression, media streaming and artificial intelligence (co-author of several papers and patents).
the author is looking for new job, my resume





My spouse and I absolutely love your blog and find a lot of your post’s to be what precisely I’m looking for. can you offer guest writers to write content for yourself? I wouldn’t mind producing a post or elaborating on most of the subjects you write with regards to here. Again, awesome web log!
I will immediately grab your rss feed as I can not find your e-mail subscription link or e-newsletter service. Do you’ve any? Please let me know in order that I could subscribe. Thanks.
go to the main page and look for the word ‘Newsletter’
you have a great blog here! would you like to make some invite posts on my blog?
i am afraid i don’t understand, you are welcome to take any content from my blog and copy-paste to yours.
Do you mind if I quote a few of your articles as long as I provide credit and sources back to your site? My blog is in the exact same area of interest as yours and my users would genuinely benefit from some of the information you present here. Please let me know if this ok with you. Appreciate it!
it’s ok, content is free
I’m extremely impressed with your writing skills as well as with the layout on your weblog. Is this a paid theme or did you modify it yourself? Either way keep up the excellent quality writing, it is rare to see a nice blog like this one today..
it’s a non-profitable site. i don’t wage money.
Pretty nice post. I just stumbled upon your weblog and wanted to say that I have truly enjoyed browsing your blog posts. In any case I will be subscribing to your feed and I hope you write again very soon!
Does your website have a contact page? I’m having a tough time locating it but, I’d like to shoot you an e-mail. I’ve got some suggestions for your blog you might be interested in hearing. Either way, great site and I look forward to seeing it improve over time.
slavah264@gmail.com
Superb post however I was wondering if you could write a litte more on this subject? I’d be very thankful if you could elaborate a little bit further. Many thanks!
Thanks for another fantastic article. Where else could anyone get that kind of info in such a perfect way of writing? I’ve a presentation next week, and I’m on the look for such info.
Keep functioning ,great job!
Great blog you have here but I was wanting to know if you knew of any message boards that cover the same topics discussed in this article? I’d really love to be a part of online community where I can get advice from other knowledgeable people that share the same interest. If you have any suggestions, please let me know. Thank you!
You made some decent points there. I looked on the internet for the issue and found most persons will consent with your website.